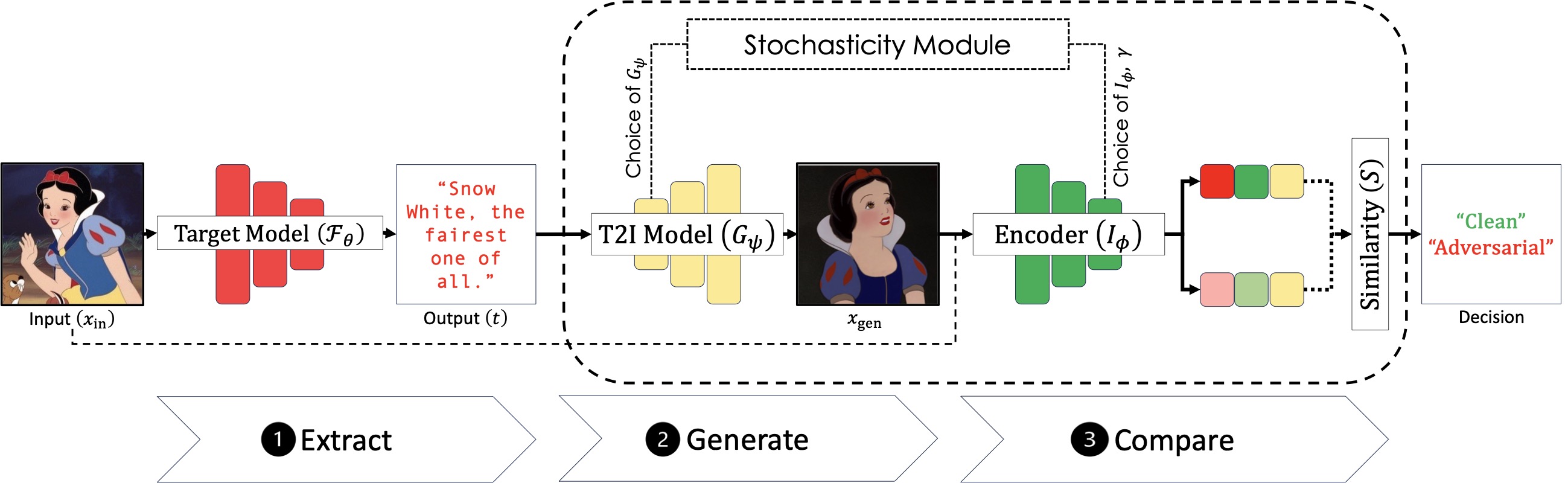
Vision-Language Models (VLMs) are increasingly susceptible to sophisticated adversarial attacks, including adaptive strategies specifically designed to bypass existing defenses. To address this vulnerability, we propose MirrorCheck, a robust and model-agnostic detection framework that operates effectively in both unimodal and multimodal settings.
MirrorCheck leverages Text-to-Image (T2I) models to regenerate visual content from captions produced by the target model and assesses semantic consistency by comparing feature-space embeddings between the original and synthesized images. To enhance robustness against adaptive attacks, MirrorCheck introduces a stochastic defense strategy that randomly selects T2I generators and image encoders from a diverse model zoo.
Additionally, we incorporate a novel One-Time-Use (OTU) perturbation applied to the selected encoder embeddings, regulated by a scaling factor, which decreases the effectiveness of adaptive attacks. Extensive experiments across multiple threat scenarios demonstrate that MirrorCheck consistently outperforms baseline methods, and maintains its utility even under strong adaptive adversarial conditions.
MirrorCheck consistently outperforms both traditional unimodal and recent multimodal baseline defenses across a wide variety of VLM architectures and attack types. Below are the comprehensive evaluation tables.
| Victim Model | Attack Setting | Unimodal Approaches | Multimodal Approaches | Ours | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FS | MagNet | PuVAE | DiffPure | CIDER | Naive | CLIP | JailGuard | SmoothVLM | DPS | MC | Stoch-MC | ||
| UniDiffuser | AttackVLM-T | 0.56 | 0.74 | 0.51 | 0.80 | 0.84 | 0.68 | 0.59 | 0.81 | 0.82 | 0.83 | 0.96 | 0.95 |
| AttackVLM-Q | 0.65 | 0.85 | 0.70 | 0.81 | 0.80 | 0.65 | 0.57 | 0.83 | 0.83 | 0.85 | 0.98 | 0.98 | |
| BLIP | AttackVLM-T | 0.52 | 0.60 | 0.50 | 0.71 | 0.81 | 0.66 | 0.61 | 0.79 | 0.77 | 0.81 | 0.90 | 0.93 |
| AttackVLM-Q | 0.57 | 0.65 | 0.80 | 0.76 | 0.85 | 0.64 | 0.55 | 0.84 | 0.81 | 0.84 | 0.89 | 0.97 | |
| BLIP-2 | AttackVLM-T | 0.61 | 0.73 | 0.52 | 0.80 | 0.84 | 0.70 | 0.62 | 0.82 | 0.80 | 0.86 | 0.93 | 0.94 |
| AttackVLM-Q | 0.61 | 0.85 | 0.72 | 0.83 | 0.77 | 0.67 | 0.58 | 0.80 | 0.78 | 0.83 | 0.92 | 0.99 | |
| Attack-Bard | - | - | - | 0.79 | 0.87 | 0.65 | 0.58 | 0.89 | 0.87 | 0.95 | 0.98 | 0.95 | |
| Img2Prompt | AttackVLM-T | 0.51 | 0.56 | 0.50 | 0.67 | 0.83 | 0.61 | 0.56 | 0.83 | 0.83 | 0.86 | 0.79 | 0.90 |
| AttackVLM-Q | - | 0.65 | 0.78 | 0.69 | 0.79 | 0.60 | 0.55 | 0.81 | 0.74 | 0.82 | 0.85 | 0.92 | |
| LLaVA | Attack-MMFM | - | - | - | 0.67 | 0.83 | 0.62 | 0.52 | 0.85 | 0.85 | 0.85 | 0.82 | 0.85 |
| OpenFlamingo | Attack-MMFM | - | - | - | 0.65 | 0.84 | 0.60 | 0.51 | 0.87 | 0.84 | 0.86 | 0.81 | 0.81 |
| MiniGPT-4 | AttackVLM-T | 0.54 | 0.51 | 0.53 | 0.62 | 0.85 | 0.57 | 0.51 | 0.85 | 0.80 | 0.85 | 0.66 | 0.67 |
Our MirrorCheck variants consistently outperform both unimodal approaches and multimodal VLM-specific methods, achieving superior detection rates as high as 0.99.
| Victim Model | Task | Attack Setting | 1 Encoder | 3 Encoders | 5 Encoders | 7 Encoders | 10 Encoders | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5e-6 | 5e-4 | 1e-3 | 5e-6 | 5e-4 | 1e-3 | 5e-6 | 5e-4 | 1e-3 | 5e-6 | 5e-4 | 1e-3 | 5e-6 | 5e-4 | 1e-3 | |||
| UniDiffuser | IC | Clean | 0.721 | 0.624 | 0.740 | 0.651 | 0.701 | 0.685 | 0.694 | 0.647 | 0.715 | 0.648 | 0.693 | 0.670 | 0.665 | 0.670 | 0.692 |
| AttackVLM-T | 0.502 | 0.341 | 0.568 | 0.370 | 0.501 | 0.477 | 0.494 | 0.399 | 0.549 | 0.402 | 0.472 | 0.458 | 0.424 | 0.441 | 0.494 | ||
| AttackVLM-Q | 0.498 | 0.294 | 0.542 | 0.336 | 0.448 | 0.395 | 0.424 | 0.332 | 0.446 | 0.340 | 0.411 | 0.375 | 0.366 | 0.372 | 0.408 | ||
| BLIP | IC | Clean | 0.707 | 0.610 | 0.730 | 0.633 | 0.686 | 0.672 | 0.676 | 0.628 | 0.700 | 0.629 | 0.675 | 0.652 | 0.647 | 0.653 | 0.676 |
| AttackVLM-T | 0.481 | 0.323 | 0.547 | 0.349 | 0.450 | 0.454 | 0.419 | 0.362 | 0.480 | 0.353 | 0.423 | 0.412 | 0.375 | 0.391 | 0.448 | ||
| AttackVLM-Q | 0.508 | 0.299 | 0.555 | 0.350 | 0.460 | 0.460 | 0.436 | 0.346 | 0.407 | 0.354 | 0.424 | 0.389 | 0.379 | 0.384 | 0.421 | ||
| BLIP-2 | IC | Clean | 0.729 | 0.636 | 0.744 | 0.655 | 0.705 | 0.687 | 0.697 | 0.664 | 0.718 | 0.651 | 0.695 | 0.684 | 0.668 | 0.675 | 0.695 |
| AttackVLM-T | 0.504 | 0.345 | 0.563 | 0.376 | 0.473 | 0.475 | 0.443 | 0.381 | 0.503 | 0.377 | 0.447 | 0.434 | 0.399 | 0.413 | 0.467 | ||
| ID | Attack-Bard | 0.484 | 0.422 | 0.536 | 0.379 | 0.444 | 0.498 | 0.399 | 0.416 | 0.468 | 0.377 | 0.451 | 0.427 | 0.399 | 0.420 | 0.461 | |
| Img2Prompt | VQA | Clean | 0.675 | 0.563 | 0.705 | 0.589 | 0.652 | 0.637 | 0.637 | 0.585 | 0.677 | 0.586 | 0.638 | 0.616 | 0.605 | 0.613 | 0.642 |
| AttackVLM-T | 0.482 | 0.317 | 0.547 | 0.345 | 0.449 | 0.455 | 0.416 | 0.359 | 0.479 | 0.349 | 0.422 | 0.412 | 0.372 | 0.388 | 0.477 | ||
| AttackVLM-Q | 0.517 | 0.309 | 0.561 | 0.361 | 0.470 | 0.467 | 0.447 | 0.356 | 0.414 | 0.365 | 0.431 | 0.396 | 0.390 | 0.392 | 0.427 | ||
| LLaVA | VQA | Clean | 0.680 | 0.823 | 0.755 | 0.733 | 0.714 | 0.741 | 0.728 | 0.810 | 0.748 | 0.725 | 0.706 | 0.733 | 0.712 | 0.798 | 0.742 |
| Attack-MMFM | 0.539 | 0.724 | 0.626 | 0.599 | 0.596 | 0.617 | 0.618 | 0.710 | 0.641 | 0.608 | 0.602 | 0.625 | 0.595 | 0.695 | 0.632 | ||
| OpenFlamingo | VQA | Clean | 0.690 | 0.817 | 0.756 | 0.728 | 0.723 | 0.743 | 0.734 | 0.804 | 0.749 | 0.720 | 0.715 | 0.735 | 0.708 | 0.791 | 0.742 |
| Attack-MMFM | 0.535 | 0.714 | 0.618 | 0.584 | 0.609 | 0.612 | 0.609 | 0.701 | 0.635 | 0.596 | 0.614 | 0.620 | 0.582 | 0.688 | 0.625 | ||
| MiniGPT-4 | VQA | Clean | 0.651 | 0.536 | 0.684 | 0.561 | 0.628 | 0.618 | 0.612 | 0.560 | 0.646 | 0.559 | 0.613 | 0.593 | 0.578 | 0.587 | 0.620 |
| AttackVLM-T | 0.568 | 0.457 | 0.620 | 0.472 | 0.548 | 0.551 | 0.523 | 0.481 | 0.576 | 0.469 | 0.532 | 0.519 | 0.489 | 0.504 | 0.549 | ||
| DenseNet | CL | Clean | 0.543 | 0.740 | 0.705 | 0.671 | 0.674 | 0.667 | 0.692 | 0.658 | 0.695 | 0.665 | 0.688 | 0.671 | 0.652 | 0.660 | 0.679 |
| FGSM | 0.444 | 0.666 | 0.572 | 0.537 | 0.548 | 0.553 | 0.579 | 0.521 | 0.584 | 0.535 | 0.572 | 0.558 | 0.518 | 0.541 | 0.567 | ||
| BIM | 0.507 | 0.713 | 0.593 | 0.554 | 0.532 | 0.579 | 0.601 | 0.542 | 0.598 | 0.548 | 0.586 | 0.571 | 0.531 | 0.553 | 0.581 | ||
| PGD | 0.495 | 0.705 | 0.585 | 0.546 | 0.524 | 0.571 | 0.593 | 0.534 | 0.590 | 0.540 | 0.578 | 0.563 | 0.523 | 0.545 | 0.573 | ||
| DeepFool | 0.475 | 0.690 | 0.565 | 0.525 | 0.510 | 0.555 | 0.575 | 0.515 | 0.570 | 0.520 | 0.560 | 0.545 | 0.505 | 0.525 | 0.555 | ||
| C&W | 0.460 | 0.680 | 0.555 | 0.515 | 0.500 | 0.545 | 0.565 | 0.505 | 0.560 | 0.510 | 0.550 | 0.535 | 0.495 | 0.515 | 0.545 | ||
| MobileNet | CL | Clean | 0.668 | 0.790 | 0.729 | 0.704 | 0.705 | 0.719 | 0.745 | 0.698 | 0.738 | 0.702 | 0.726 | 0.712 | 0.688 | 0.695 | 0.721 |
| FGSM | 0.520 | 0.712 | 0.606 | 0.612 | 0.585 | 0.607 | 0.635 | 0.598 | 0.629 | 0.605 | 0.618 | 0.610 | 0.585 | 0.592 | 0.615 | ||
| BIM | 0.503 | 0.693 | 0.581 | 0.565 | 0.538 | 0.576 | 0.605 | 0.572 | 0.598 | 0.575 | 0.590 | 0.582 | 0.558 | 0.565 | 0.585 | ||
| PGD | 0.495 | 0.685 | 0.573 | 0.557 | 0.530 | 0.568 | 0.597 | 0.564 | 0.590 | 0.567 | 0.582 | 0.574 | 0.550 | 0.557 | 0.577 | ||
| DeepFool | 0.475 | 0.670 | 0.555 | 0.540 | 0.515 | 0.552 | 0.580 | 0.548 | 0.573 | 0.550 | 0.565 | 0.557 | 0.535 | 0.542 | 0.562 | ||
| C&W | 0.465 | 0.660 | 0.545 | 0.530 | 0.505 | 0.542 | 0.570 | 0.538 | 0.563 | 0.540 | 0.555 | 0.547 | 0.525 | 0.532 | 0.552 | ||
Results shown for random CLIP encoder selection with One-Time-Use perturbations across different ensemble sizes and noise scales. Clean images consistently achieve high similarity scores, while adversarial examples show degraded similarity.
| Victim Model | Setting | 1 Encoder | 3 Encoders | 5 Encoders | 7 Encoders | 10 Encoders | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5e-6 | 5e-4 | 1e-3 | 5e-6 | 5e-4 | 1e-3 | 5e-6 | 5e-4 | 1e-3 | 5e-6 | 5e-4 | 1e-3 | 5e-6 | 5e-4 | 1e-3 | ||
| UniDiffuser | AttackVLM-T | 0.913 | 0.895 | 0.903 | 0.925 | 0.943 | 0.858 | 0.933 | 0.890 | 0.910 | 0.908 | 0.912 | 0.915 | 0.920 | 0.918 | 0.917 |
| AttackVLM-Q | 0.955 | 0.902 | 0.968 | 0.952 | 0.968 | 0.937 | 0.973 | 0.975 | 0.980 | 0.977 | 0.978 | 0.980 | 0.975 | 0.973 | 0.992 | |
| BLIP | AttackVLM-T | 0.905 | 0.908 | 0.908 | 0.918 | 0.932 | 0.903 | 0.922 | 0.915 | 0.925 | 0.930 | 0.930 | 0.918 | 0.930 | 0.923 | 0.925 |
| AttackVLM-Q | 0.928 | 0.887 | 0.943 | 0.913 | 0.937 | 0.915 | 0.958 | 0.943 | 0.963 | 0.962 | 0.947 | 0.955 | 0.965 | 0.945 | 0.955 | |
| BLIP-2 | AttackVLM-T | 0.912 | 0.892 | 0.912 | 0.920 | 0.932 | 0.907 | 0.923 | 0.923 | 0.928 | 0.927 | 0.935 | 0.932 | 0.930 | 0.927 | 0.938 |
| AttackVLM-Q | 0.945 | 0.903 | 0.967 | 0.948 | 0.957 | 0.932 | 0.975 | 0.970 | 0.985 | 0.982 | 0.978 | 0.977 | 0.978 | 0.970 | 0.990 | |
| Attack-Bard | 0.883 | 0.790 | 0.827 | 0.890 | 0.873 | 0.900 | 0.903 | 0.952 | 0.903 | 0.942 | 0.913 | 0.902 | 0.927 | 0.920 | 0.938 | |
| Img2Prompt | AttackVLM-T | 0.848 | 0.840 | 0.843 | 0.878 | 0.873 | 0.853 | 0.882 | 0.860 | 0.867 | 0.878 | 0.875 | 0.883 | 0.895 | 0.878 | 0.882 |
| AttackVLM-Q | 0.880 | 0.806 | 0.907 | 0.861 | 0.863 | 0.855 | 0.886 | 0.857 | 0.905 | 0.870 | 0.877 | 0.905 | 0.887 | 0.882 | 0.920 | |
| LLaVA | Attack-MMFM | 0.788 | 0.728 | 0.733 | 0.812 | 0.762 | 0.738 | 0.818 | 0.812 | 0.783 | 0.832 | 0.815 | 0.812 | 0.845 | 0.833 | 0.820 |
| OpenFlamingo | Attack-MMFM | 0.800 | 0.740 | 0.765 | 0.777 | 0.750 | 0.750 | 0.807 | 0.785 | 0.767 | 0.800 | 0.780 | 0.797 | 0.797 | 0.793 | 0.785 |
| MiniGPT-4 | AttackVLM-T | 0.642 | 0.623 | 0.632 | 0.660 | 0.660 | 0.642 | 0.655 | 0.665 | 0.667 | 0.655 | 0.665 | 0.657 | 0.655 | 0.665 | 0.655 |
| DenseNet | FGSM | 0.850 | 0.840 | 0.800 | 0.845 | 0.835 | 0.795 | 0.852 | 0.842 | 0.802 | 0.847 | 0.837 | 0.798 | 0.849 | 0.839 | 0.801 |
| BIM | 0.860 | 0.830 | 0.830 | 0.855 | 0.825 | 0.825 | 0.862 | 0.832 | 0.832 | 0.857 | 0.827 | 0.828 | 0.859 | 0.829 | 0.831 | |
| PGD | 0.845 | 0.825 | 0.815 | 0.840 | 0.820 | 0.810 | 0.847 | 0.827 | 0.817 | 0.842 | 0.822 | 0.812 | 0.844 | 0.824 | 0.814 | |
| DeepFool | 0.835 | 0.815 | 0.795 | 0.830 | 0.810 | 0.790 | 0.837 | 0.817 | 0.797 | 0.832 | 0.812 | 0.792 | 0.834 | 0.814 | 0.794 | |
| C&W | 0.825 | 0.805 | 0.785 | 0.820 | 0.800 | 0.780 | 0.827 | 0.807 | 0.787 | 0.822 | 0.802 | 0.782 | 0.824 | 0.804 | 0.784 | |
| MobileNet | FGSM (0.3) | 0.780 | 0.770 | 0.750 | 0.775 | 0.765 | 0.745 | 0.782 | 0.772 | 0.752 | 0.777 | 0.767 | 0.747 | 0.779 | 0.769 | 0.749 |
| FGSM (0.1) | 0.850 | 0.850 | 0.790 | 0.845 | 0.845 | 0.785 | 0.852 | 0.852 | 0.792 | 0.847 | 0.847 | 0.787 | 0.849 | 0.849 | 0.789 | |
| BIM | 0.790 | 0.790 | 0.780 | 0.785 | 0.785 | 0.775 | 0.792 | 0.792 | 0.782 | 0.787 | 0.787 | 0.777 | 0.789 | 0.789 | 0.779 | |
| PGD | 0.775 | 0.775 | 0.765 | 0.770 | 0.770 | 0.760 | 0.777 | 0.777 | 0.767 | 0.772 | 0.772 | 0.762 | 0.774 | 0.774 | 0.764 | |
| DeepFool | 0.760 | 0.750 | 0.740 | 0.755 | 0.745 | 0.735 | 0.762 | 0.752 | 0.742 | 0.757 | 0.747 | 0.737 | 0.759 | 0.749 | 0.739 | |
| C&W | 0.745 | 0.735 | 0.725 | 0.740 | 0.730 | 0.720 | 0.747 | 0.737 | 0.727 | 0.742 | 0.732 | 0.722 | 0.744 | 0.734 | 0.724 | |
The method achieves consistently high detection rates (65-99%) across VLM attacks (AttackVLM, Attack-Bard, Attack-MMFM) and classification attacks (FGSM, BIM, PGD, DeepFool, C&W), demonstrating robust performance with randomized encoder selection and One-Time-Use perturbations.
Visual comparison showing the MirrorCheck pipeline in action using BLIP as the victim model and Stable Diffusion as the T2I generator. For clean images, the regenerated image shares strong semantic similarities with the original. Under an adversarial attack, the forced incorrect caption leads to a completely disconnected regeneration, triggering the detection.




















@inproceedings{fares2026mirrorcheck,
title={MirrorCheck: Efficient Adversarial Defense for Vision-Language Models},
author={Samar Fares and Klea Ziu and Toluwani Aremu and Nikita Durasov and Martin Tak{\'a}{\v{c}} and Pascal Fua and Karthik Nandakumar and Ivan Laptev},
booktitle={The 6th Workshop of Adversarial Machine Learning on Computer Vision: Safety of Vision-Language Agents},
year={2026},
url={https://arxiv.org/abs/2406.09250}
}